
Liran Bar, Director of Product Marketing, CEVA
Artificial intelligence on mobile devices is no longer dependent on cloud connectivity. This year’s CES’s hottest product demos and recently announced flagship smartphones have demonstrated this view. Artificial intelligence has entered terminal equipment and quickly became a market selling point. These factors, including security, privacy and response time, will surely continue to expand this trend to more end devices. In order to meet the demand, players in almost every chip industry have introduced different versions and differently named artificial intelligence processors, such as “deep learning engineâ€, “neural processorâ€, “artificial intelligence engine†and so on.

However, not all artificial intelligence processors are the same. The reality is that many so-called artificial intelligence engines are traditional embedded processors (using CPUs and GPUs) plus a Vector Vector Processing Unit (VPU). The VPU unit is designed to efficiently perform heavy computational loads related to computer vision and deep learning. Although having a powerful, low-power VPU is an important part of embedded artificial intelligence, this is not the whole story. The VPU is one of many components that make up an outstanding artificial intelligence processor. Although the VPU has been carefully designed and does provide the required flexibility, it is not an AI processor. There are some other features here that are critical to the front-end processing of artificial intelligence.
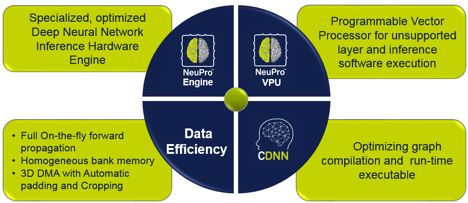
NeuProTM - CEVA AI (Machine Learning) Total Solution' (Photo courtesy of CEVA)
Optimize the workload of embedded systems
In the cloud computing process, floating-point calculations are used for training, and fixed-point calculations are used for reasoning to achieve maximum accuracy. With large server groups for data processing, energy consumption and size must be considered, but they are almost infinite compared to processes with edge constraints. On mobile devices, the feasibility of power, performance, and area (PPA) design is crucial. Therefore, on the embedded SoC chip, more efficient fixed-point calculations are preferred. When the network is converted from floating point to fixed point, some precision will inevitably be lost. However, the correct design can minimize the loss of precision and can achieve almost the same results as the original training network.
One way to control accuracy is to choose between 8-bit and 16-bit integer precision. Although 8-bit precision can save bandwidth and computing resources, many commercial neural networks still need to use 16-bit precision to ensure accuracy. Each layer of the neural network has different constraints and redundancy, so it is crucial to choose the best accuracy for each layer.

Choose the best accuracy in layers (images from CEVA)
For developers and SoC designers, a tool that automatically outputs optimized graphical compilers and executables, such as the CEVA network generator, is a huge advantage from a time-to-market perspective. In addition, it is also important to maintain the flexibility to choose the best accuracy (8-bit or 16-bit) for each layer. This allows each layer to trade off between optimization accuracy and performance, and then one-click generation of efficient and accurate embedded network reasoning.
Dedicated hardware to handle true artificial intelligence algorithms
The VPU is flexible, but many of the most common neural networks require a large number of bandwidth channels to challenge the standard processor instruction set. Therefore, special hardware must be available to handle these complex calculations.
For example, the NeuPro AI processor includes a dedicated engine that handles matrix multiplication, a fully connected layer, an active layer, and a convergence layer. This advanced dedicated AI engine combined with the fully programmable NeuPro VPU can support all other layer types and neural network topologies. The direct connection between these modules allows data to be exchanged seamlessly and no longer needs to be written to memory. In addition, optimized DDR bandwidth and advanced DMA controllers use dynamic pipeline processing to further increase speed while reducing power consumption.
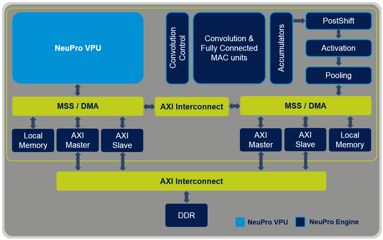
NeuPro AI processor block diagram combined with NeuPro engine and NeuPro VPU (Photo: CEVA)
Unknown artificial intelligence algorithm tomorrow
Artificial intelligence is still a new and rapidly developing field. The application scenarios of neural networks are rapidly increasing, such as target recognition, speech and sound analysis, 5G communication, and the like. Maintaining an adaptable solution to meet future trends is the only way to ensure successful chip design. Therefore, dedicated hardware that satisfies the existing algorithms is certainly not enough, and it must be matched with a fully programmable platform. In the context of continuous improvement of algorithms, computer simulations are key tools for making decisions based on actual results and reduce time-to-market. The CDNN PC Emulation Package allows SoC designers to use the PC environment to weigh their designs before developing real hardware.
Another valuable feature that meets future needs is scalability. The NeuPro AI product family can be applied to a wide range of target markets, from lightweight IoT and wearable devices (2TOPs) to high-performance industry surveillance and autopilot applications (12.5 TOPs).
The race to implement the flagship AI processor on the mobile has begun. Many people quickly caught up to this trend and used artificial intelligence as their selling point, but not all products have the same level of intelligence. If you want to create a smart device that stays "smart" in the evolving field of artificial intelligence, you should make sure to check all the features mentioned above when selecting an AI processor.
Spring-type terminals are new types of spring-type terminals, which have been widely used in the world's electrical and electronic engineering industries: lighting, elevator control, instrumentation, power, chemistry, and automotive power.
If the terminal block is black, one of the possibilities is not necessarily burning black, oxidation may also be black. So how to verify whether it is burnt black? The method we take is to wipe it with a finger. If it can be wiped off, like soot, it is the black substance formed by oxidation, which can only be ground off with sandpaper or a file.
Spring Terminal,Spring Push-In Terminal Block,Spring Clamp Terminal Block,Spring Terminal Block For Pcb
Sichuan Xinlian electronic science and technology Company , https://www.sztmlch.com