
After the face test mentioned earlier, the face is extracted and saved for training or recognition. The code for extracting the face is as follows:
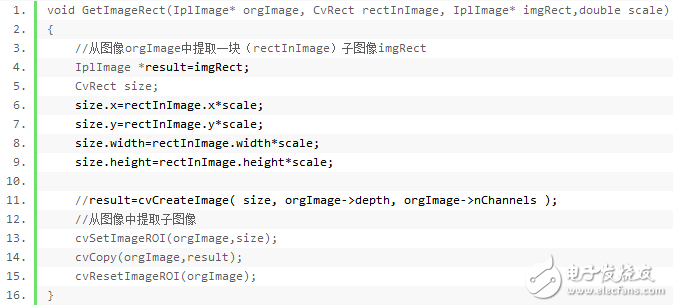
Face preprocessing
Now that you have got a face, you can use that face image for face recognition. However, if you try to perform face recognition directly from a normal picture, you will lose at least 10% accuracy!
In a face recognition system, it is extremely important to apply a variety of preprocessing techniques to standardize the pictures to be recognized. Most face recognition algorithms are very sensitive to lighting conditions, so if you train in a dark room, you may not be recognized in a bright room. This problem can be attributed to "luminaTIon dependent", and there are many other examples, such as the face should also be in a very fixed position of the picture (such as the same pixel coordinates of the eye position), fixed size, rotation angle, hair and decoration. , expressions (laughs, anger, etc.), the direction of the light (left or up, etc.), which is why it is important to use good image preprocessing filters before face recognition. You should also do other things, such as removing extra pixels around the face (such as elliptical masks, showing only the inner face area instead of the hair or picture background because they change more than the face area).
For the sake of simplicity, the face recognition system I showed you is a feature face method that uses grayscale images. So I will show you how to simply convert a color image into a grayscale image, and then simply use Histogram EqualizaTIon as an automatic method for normalizing the brightness and contrast of facial images. For better results, you can use color face recogniTIon (ideal with color histogram fit TIng in HSV or another color space instead of RGB), or use more preprocessing, such as edge enhancement. , contour detection, motion detection, and so on.
PCA principle
Now that you have a pre-processed face image, you can use Face Detection (PCA) for face recognition. OpenCV comes with the "cvEigenDecomposite()" function that performs PCA operations, but you need a picture database (training set) to tell the machine how to identify the person in it.
So you should collect a set of pre-processed facial images for each person for identification. For example, if you want to identify someone from a class of 10 people, you can store 20 images for each person, for a total of 200 pre-processed face images of the same size (eg 100 x 100 pixels).
The theory of eigenfaces is explained in two articles by Servo Magazine (Face Recognition with Eigenface), but I will still try to explain it to you here.
We use Principal Component Analysis to convert your 200 training images into a set of "feature faces" that represent the main differences between these training images. First it will generate an "average face image" of these images by taking the average of each pixel. The feature face will then be compared to the "average face". The first feature face is the most important face difference, the second feature face is the second most important face difference, etc... until you have about 50 feature faces that represent the difference of most training set images.
In the sample images above you can see the average face and the first and last feature faces. Note that the average face shows a smooth face structure of an ordinary person, some of the top face features show some major facial features, and the last feature face (such as Eigenface 119) is mainly image noise. You can see the top 32 feature faces below.
Simply put, the Principal Component Analysis calculates the main differences in the images in the training set and uses these "different" combinations to represent each training picture.
For example, a training picture might look like this:
(averageFace) + (13.5% of eigenface0) – (34.3% of eigenface1) + (4.7% of eigenface2) + ... + (0.0% of eigenface199).
Once calculated, you can think of this training picture as the 200 ratios:
{13.5, -34.3, 4.7, ..., 0.0}.
Multiplying these ratios with feature face images and adding an average face image, it is perfectly possible to restore this training picture from these 200 ratios. However, since many of the feature faces that are behind are image noise or do not have much effect on the image, the ratio table can be reduced to only the most important ones, such as the top 30, which will not have a significant impact on image quality. . So now you can use 30 feature faces, average face images, and a table with 30 ratios to represent all 200 training images.
Identifying a person in another picture, you can apply the same PCA calculation, using the same 200 feature faces to find the ratio of 200 representative input pictures. And you can still keep only the first 30 ratios and ignore the rest because they are secondary. Then by searching the tables for these ratios, look for 20 people known in the database to see who has the top 30 ratios closest to the top 30 ratios of the input images. This is the basic method of finding the most similar training picture with the input picture, providing a total of 200 training pictures.
Training picture
Creating a face recognition database is to train a text file that lists the image files and the people represented by each file to form a facedata.xml "file.
For example, you can enter these into a text file called "trainingphoto.txt":
Joke1.jpg
Joke2.jpg
Joke3.jpg
Joke4.jpg
Lily1.jpg
Lily2.jpg
Lily3.jpg
Lily4.jpg
It tells the program that the first person's name is "joke, and the joke has four pre-processed face images, the second person's name is "lily", and she has four pictures. This program can be used" The loadFaceImgArray()" function loads these images into an image array.
To create a database from these loaded images, you can use OpenCV's "cvCalcEigenObjects()" and "cvEigenDecomposite()" functions.
Get the function of the feature space:
Void cvCalcEigenObjects( int nObjects, void* input, void* output, int ioFlags, int ioBufSize, void* userData,CvTermCriteria* calcLimit, IplImage* avg, float* eigVals )
nObjects: The number of targets, that is, the number of input training pictures.
Input: Enter the image of the training.
Output: output feature face, a total of nEigens
ioFlags, ioBufSize: defaults to 0
userData: Pointer to the data structure body that points to the callback function.
A transmitter sends both audio and video signals over the air waves. Transmitters usually transmit more than one signal (TV channel) at a time. A transmitter modulates both picture and sound into one signal and then send this transmission over a wide range to be received by a receiver (TV set).
It is an electronic device that radiates radio waves that carry a video signal representing moving images, along with a synchronized audio channel, which is received by television receivers ('televisions' or 'TVs') belonging to a public audience, which display the image on a screen.
Dtv Transmitter,Vhf Uhf Tv Transmitter,Terrestrial Tv Transmitter,Tv Channel Transmitter
Anshan Yuexing Technology Electronics Co., LTD , https://www.yxhtfmtv.com