
For data scientists, it is very important to understand statistical phenomena and ask "why".
Imagine a scene like this: one day, you and a friend have an appointment to have dinner together, and you both want to find a perfect restaurant. Due to too many options, the two people may not have the same taste today. In order to avoid hours of argument, you conservatively adopted a method commonly used by modern people: check food reviews.
After seeing all the restaurants with the same app, you finally locked two of them: Carlo's restaurant and Sophia restaurant. You prefer Carlo's, because from the gender data, whether it is male diners or female diners, they give a higher rate of praise (for example: male praise rate = number of male reviews/total number of male reviews); and you 'S friends are more inclined to Sophia, because he found that overall, Sophia's praise rate is higher, and the taste should be more popular.
So what is going on? Is the APP statistics wrong? In fact, these two statistical conclusions are correct, but you have entered the Simpson Paradox without knowing it. Here, we can use exactly the same set of data to prove two completely opposite arguments.
What is Simpson's Paradox?
The Simpson Paradox is named after the British statistician EH Simpson (EHSimpson). This is a phenomenon he explained in 1951: When we count the same data set in two ways, grouping and aggregation, the two trends finally come out It may be completely reversed. In the "dining" case above, Carlo's restaurant has a higher recommendation rate for both sexes, but its overall recommendation rate is lower. If you don't want to be stunned, we can use some intuitive data to illustrate:
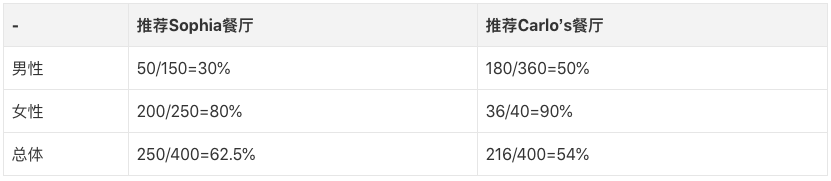
The above table clearly shows that when the data is grouped, Carlo's is the first choice, but when the data is combined, Sophia is the first choice!
The reason for this paradox is the sample size. When we group the statistics, Carlo's restaurant has a female recommendation rate as high as 90%, but its sample is only 40, accounting for only 10% of the total number of reviews; while the female recommendation rate of Sophia restaurant is only 80%, but female reviewers There are 250, which obviously will greatly increase the overall praise rate of the restaurant.
Therefore, when selecting a restaurant, we must determine in advance whether the statistical method of data is more reasonable to combine or group to be more reasonable-this depends on the process of data generation, that is, the causal model of the data.
Reversal of correlation
In our lives, another common Simpson paradox is that after grouping and aggregating and discussing data, the correlation between elements has also been reversed. To give a simple example, suppose we have two groups of patients over 50 years old and under 50 years old. After collecting their weekly exercise hours and disease risk, we get the following two pictures about the relationship between exercise and the probability of disease deterioration chart:
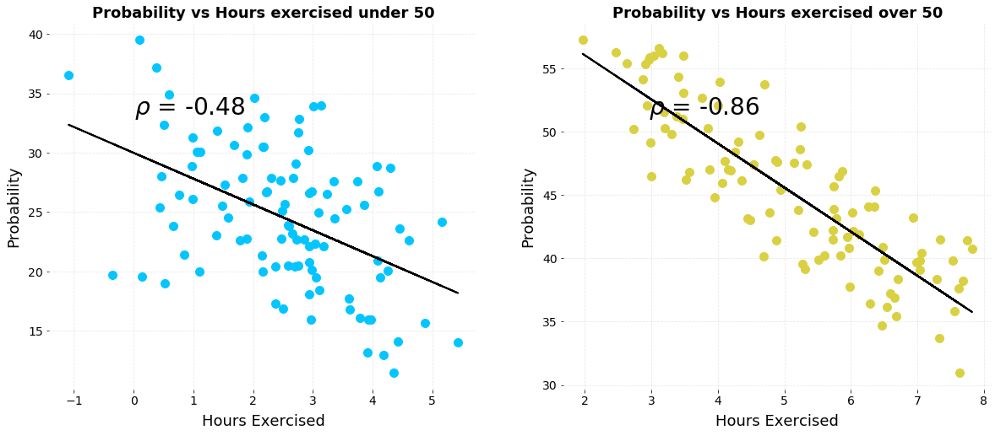
Left: under 50 years old; right: over 50 years old (the abscissa is the number of hours of exercise, the ordinate is the risk of deterioration)
The above figure clearly shows that the two are negatively correlated. The longer you exercise each week, the less likely the patient's condition will get worse. However, if we combine the two sets of data:
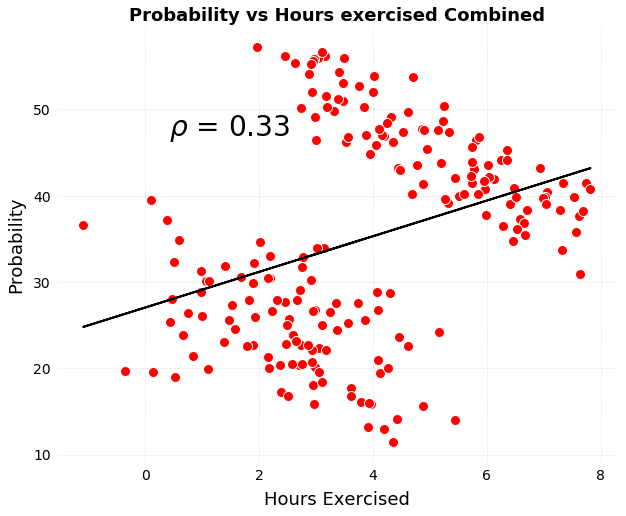
The relationship between the number of hours of exercise for patients of all ages and the probability of disease deterioration
The correlation between exercise and worsening condition is completely reversed! If we only present this picture, we will finally conclude that exercise increases the chance of deterioration. The same set of data has completely different conclusions. Similarly, the problem with this example lies in the data generation process-we have not been able to collect complete cause data, and naturally we cannot explain the final result.
Solving the paradox
In order to avoid Simpson's paradox leading us to two opposite conclusions, the most direct method is to decide whether to group or aggregate. This seems simple, but it is not easy to do. To do the right-choice questions, we must first consider the causality: how is the data generated? What are the factors that affect the results? Which ones are we not presenting?
Taking the analysis of exercise and the deterioration of the disease as an example, it is obvious that exercise is certainly not the only factor that affects the aggravation of the disease. Diet, environment, genetics... its influencing factors are very complicated. But in the above figure, we only see the relationship between the probability of deterioration and the duration of exercise. Without control variables, this is equivalent to assuming that the deterioration is only caused by exercise, which is obviously unreasonable.
For example, if we consider the neglected factor in the original data: age.
From the figure below, we can find that whether it is under 50 years old or over 50 years old, the age of the patient and the probability of deterioration of the disease show a strong positive correlation. This means that as patients age, even if the amount of exercise per week is the same, older patients are more likely to get worse than younger patients.
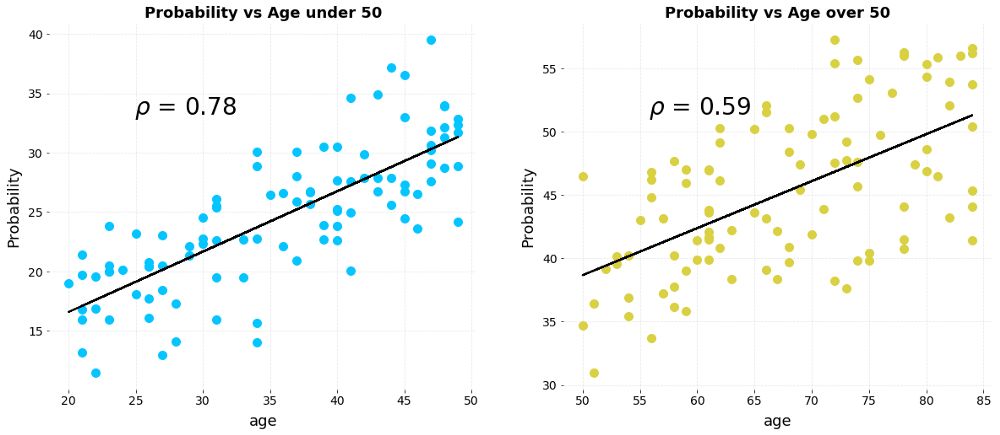
Diagram of the relationship between the patient’s age and the probability of getting worse
In this case, group discussion data is a way to circumvent Simpson's paradox. This is the same as doing scientific experiments. Whenever the data involves causality, we should control the variables before analysis to ensure reasonable stratification of the data.
In the example of choosing a restaurant, the way to solve the paradox is to re-examine the problem you want to solve-since the goal is to choose the perfect restaurant, strive to popularize the taste, and avoid thundering, the gender statistics are of little significance. In that case, aggregated data makes the most sense.
Simpson's paradox in real life
Seeing this, some readers may think that this paradox is too simple. It should be just a concept in statistics. It is impossible for anyone to make this mistake. But in fact, in the real world, we do have many famous Simpson's paradox studies.
A typical example is the choice between two treatment options for kidney stones. According to clinical trial data, doctors found that in the treatment of small stones and large stones, plan A has a better effect; but if the two types of kidney stones are combined, the cure rate of plan B is higher. The following is the specific data:

If it were you, which treatment would you choose? This problem should be combined with the data generation process in the medical field-causal model. In actual operation, in terms of serious illness, large stones are definitely much more serious than small stones, and plan A is more invasive than plan B (medical with certain traumatic treatment measures). Therefore, if the patient's kidney stones are very small, the doctor will generally be conservative and adopt plan B; and if the patient's kidney stones are large, the doctor will directly use the best plan A.
As Plan A is more suitable for severe cases, its overall cure rate will definitely be lower than Plan B.
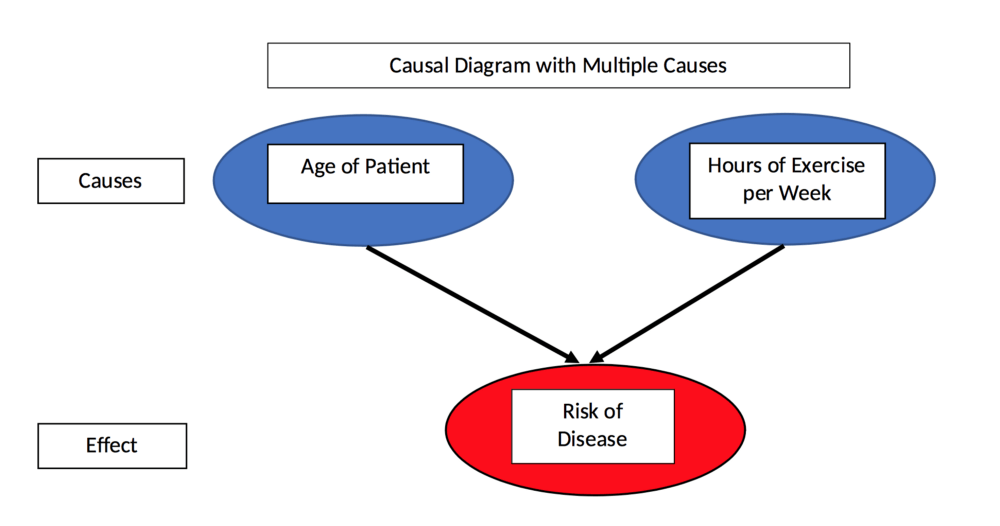
We call the "severity of the disease" in this example a confounding variable because it is related to both the independent variable (treatment plan) and the dependent variable (cure). We can't see this variable directly from the data, but if you draw a causality diagram, everything is clear:
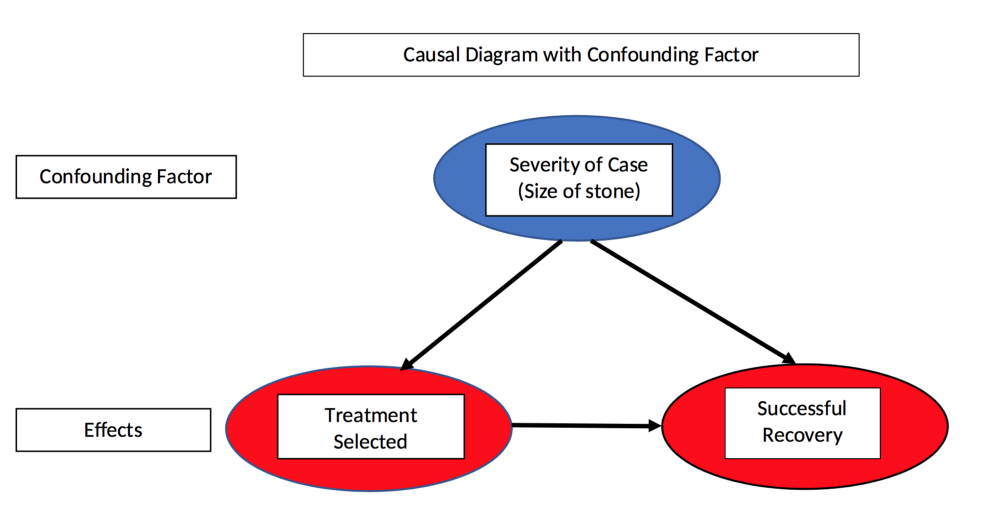
Causality diagrams and confounding variables
As shown in the figure above, the cure rate of the two programs is affected by the selected treatment program and the size of the stone, and the choice of the treatment program itself is also affected by the size of the stone. This means that if a comprehensive quantitative experiment is to be done, we must control the size of the stones and compare the cure rates of the two options. According to the experimental results, the effect of scheme A is better.
If we don't do experiments, we can answer this question in a different way. If the patient's stones are smaller, plan A with a higher cure rate is better; if the patient's stones are larger, plan A is better. Since patients will definitely have large or small stones, on the whole, option A is definitely the best option.
Sometimes it is useful to look at aggregated data, but in some cases, it can also obscure the truth of the event.
Another real case
The second realistic case is Simpson's paradox in political views. The following table shows the changes in taxes and tax rates during Gerald Ford’s presidency of the United States. It can be found that from 1974 to 1978, the tax rate of each income group has decreased to varying degrees, but the overall tax rate of society has increased.
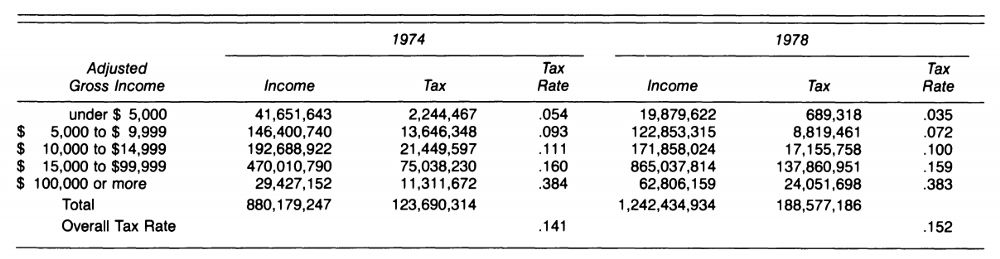
All personal tax rates have fallen, but overall tax rates have risen
According to the previous introduction, after reading this, I believe you should have learned how to explain this paradox: looking for other factors that affect the overall tax rate. The overall social tax rate is a function of two factors. It is related to the tax rate of each income group and the total income of each income group. In 1978, due to inflation in the United States, there was a significant increase in the wages of residents. The overall national income increased, and the tax rate for high-income groups was reduced. The overall tax rate in the country actually increased.
In addition to the data generation process, whether to aggregate the data should also depend on the questions we want to answer. Taking the example of taxation as an example, at the personal level, we are only individuals, so we only care about our own tax rate. But in order to determine whether we are paying more taxes, we should also pay attention to the increase in wages in addition to observing changes in tax rates. There are two important factors that affect the tax rate, and the table only provides one of them, and the resulting statistical results are inaccurate.
The importance of Simpson's paradox
The Simpson Paradox is very important because it reminds us all the time that the data shown in the table may not be all the data. We can't just be satisfied with numbers and data, but must pay attention to the process of data generation-causal model-responsible for the data. In universities, thinking about causality is not a skill that most data scientists will learn in class, but it can effectively prevent us from drawing wrong conclusions from numbers. A really good data scientist is not only an expert in data analysis, he can also combine his professional knowledge to make better decisions.
Data is a powerful weapon. It can be a tool to help us understand the world, or it can be an accomplice for others to fool us. We must always remain skeptical of data, think rationally, and ask more "why".
Smoke Detector Battery,Smoke Alarm Battery,Cr17345 Lithium Battery,Cr2 3V Lithium Battery
Jiangmen Hongli Energy Co.ltd , https://www.honglienergy.com