
Editor's note: Image completion is a hot research field. In April this year, NVIDIA published a wonderful paper: Image Inpainting for Irregular Holes Using Partial Convolutions. The article pointed out that in the past, image completion techniques used effective pixel statistical information around the incomplete position to fill the target area. Although the result is smooth, this method has the disadvantages of unrealistic effects, artifacts, and expensive post-processing. Therefore, they trained a deep neural network with a large number of irregular mask images, which can generate a reasonable mask for the image, and combined with partial convolutions only based on effective pixels, the final image completion effect of the model is far Achievements ahead of others.
Recently, some netizens reproduced this paper and published his Keras implementation on GitHub. Interested readers should check it out: github.com/MathiasGruber/PConv-Keras
NVIDIA paper
environment
Python 3.6
Keras 2.2.0
Tensorflow 1.8
How to use this repo
The PConv2Dkeras implementation included in the repo can be found in libs/pconv_layer.py and libs/pconv_model.py. In addition, the author also provides four jupyter NoteBooks, which describe in detail the steps to be taken when implementing the network, namely:
step 1: Create a random irregular mask
step 2: Implement and test the PConv2D layer
Step 3: Implement and test the PConv2D layer using UNet architecture
Step 4: Train and test the final model on ImageNet
Implementation details
When designing an image completion algorithm, researchers must first consider two factors: where to find the available information; how to judge the overall completion effect. Whether it is a naturally damaged image or an image that has been artificially mosaicked, this involves the prediction of image semantics.
Before the publication of this paper, one of the most advanced methods of image completion in the academic world was to use the pixel statistics of the remaining images to fill in the missing parts. This took advantage of the connectivity between pixels in the same image, but the disadvantage was that it only reflected statistics. It is impossible to truly realize the semantic estimation. Later, someone introduced a deep learning method and trained a deep neural network to learn semantic a priori and meaningful hidden representations in an end-to-end manner, but it is still limited to the initial value and uses a fixed replacement value. The effect Still not good.
NVIDIA proposed a new technique in the paper: add a partial convolutional layer (Partial Convolutional Layer), and add a mask update step after this layer. Part of the convolutional layer includes mask generation and renormalization, which is similar to segmentation-aware convolutional in image semantic segmentation tasks, which can segment image information without changing the input mask.
In short, given a binary mask, the convolution result of some convolutional layers only depends on the non-incomplete area of ​​each layer. Compared with segmentation-aware convolutional, NVIDIA's innovation is the automatic mask update step, which can eliminate any mask that can be partially convolutional to operate on non-mask values.
The specific design process can be viewed in the paper. Below we only summarize some details.
Generate mask
In order to train a deep neural network that can generate irregular masks, the researchers in the thesis intercepted two consecutive frames in the video and used occlusion/unocclusion to create a large number of irregular masks, although they said in the paper that this data set will be published. But now we can't find relevant resources.
In this Keras implementation, the author simply created an occlusion generation function and used OpenCV to draw some random irregular shapes as mask data. The effect seems to be pretty good.
Partial convolutional layer
The most critical part of this realization is the focus of the paper "partial convolutional layer". Basically, given the convolution filter W and the corresponding deviation b, the form of partial convolution is:
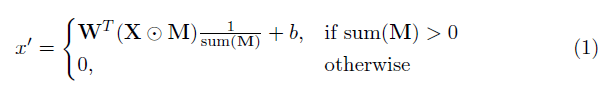
Where ⊙ stands for dot multiplication, that is, each matrix element is correspondingly multiplied, and M is a binary mask composed of 0 and 1. After each partial convolution operation is completed, the mask needs to be updated in a round. This means that if the convolution can adjust its output on at least one valid input, remove the mask at that position:
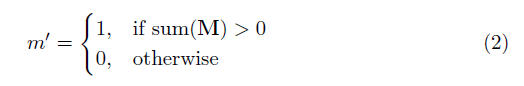
The result of this is that if the network is deep enough, the final mask will all be 0 (disappeared).
UNet architecture
The figure below is the overall architecture of PConv provided in the paper. It is similar to UNet, except that all normal convolutional layers are replaced by partial convolutional layers, so that the image + mask can pass through the network together at any time
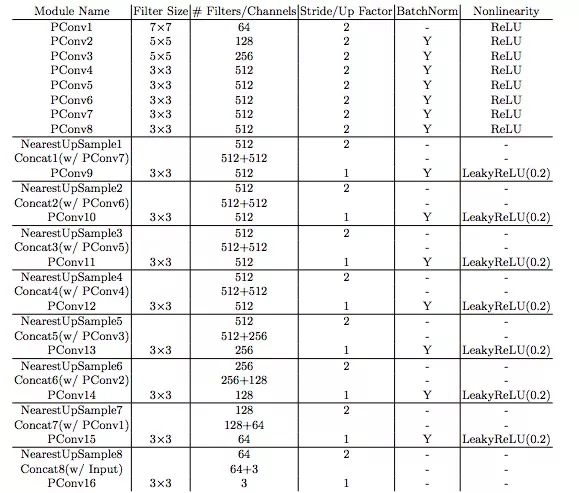
PConv overall architecture
PConv color diagram
Loss function
The losses involved in the thesis are very diverse. In short, it includes:
Loss of each pixel in the masked area (Lhole) and non-masked area (Lvalid)
Perceptual loss of VGG-16 (pool1, pool2 and pool3 layers) based on ImageNet pre-training (Lperceptual)
The style loss of VGG-16 on the predicted image (Lstyleout) and the calculated image (Lstylecomp) (using non-incomplete pixels as the true value)
The total variation loss (Ltv) of the expansion of each pixel in the incomplete area, which is the smoothing penalty of the expansion area of ​​1 pixel
The weights of the above losses are as follows:
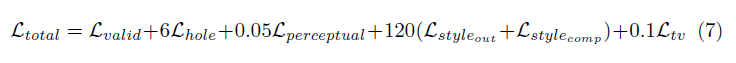
Thesis completion effect
The following figure shows the image completion effect presented in the paper. The first column is the input image, the second column is the output of the GntIpt algorithm, the third column is the result of the NVIDIA paper, and the fourth column is the real complete image. It can be found that no matter how irregular the missing area of ​​the image, PConv's completion effect is more realistic in color, texture, and shape, and it is smoother and smoother.
summary
The last and most important point is that if the model is trained on a single 1080Ti, the batch size is 4, and the total time for model training is about 10 days. This is the data that meets the paper. So if some readers want to get started, remember to prepare the hardware and time in advance.
Plastic Speakers,Plastic Speaker With Labtop,Plastic Abs Speaker,Portable Plastic Speaker
Comcn Electronics Limited , https://www.comencnspeaker.com