
On June 14, 2018, Tuya and Lunzhi jointly organized an online public course on deep learning video image compression. The lecturer is Dr. Zhou Lei, a deep learning algorithm researcher at Tuya Technology. The following are lecture notes compiled by Lunzhi. Due to the limited level, errors and omissions are unavoidable, which are for reference only.
Traditional image and video compression technology
First, we briefly review the traditional image and video compression technology.
JPEG
The following is a schematic diagram of the JPEG encoding and decoding process.
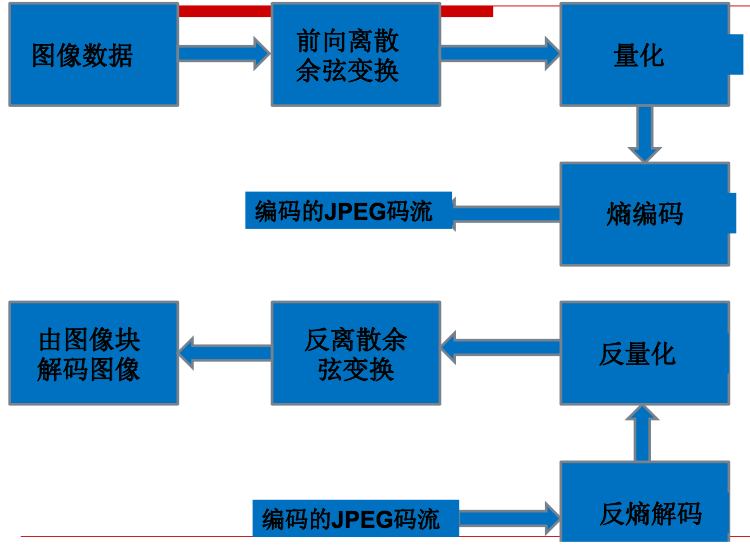
From the figure above, we can see that the image data encoding process is as follows:
Discrete cosine transform. Simply put, discrete cosine transform is a matrix operation.
After the discrete cosine transform, the high-frequency data and the low-frequency data are separated. The upper left of the matrix is ​​the high-frequency data (larger value), and the lower-right is the low-frequency data (smaller value). In this way, we can quantize it. In JPEG, it is divided by the quantization step size and then rounded.
After quantization, it is entropy coded to obtain a compressed representation.
The decoding process is inverse to the encoding process, and the image is reconstructed through anti-entropy coding, inverse quantization, and inverse discrete cosine transform.
JPEG2000
The biggest difference between JPEG2000 and JPEG is the use of discrete wavelet transform. In addition, some pre-processing steps have been added.
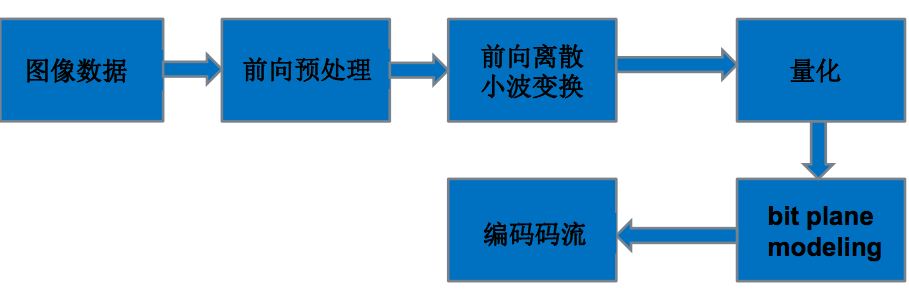
Schematic diagram of JPEG2000 encoding process
WebP
WebP is a picture compression format derived from VP8. The main feature is based on block prediction.
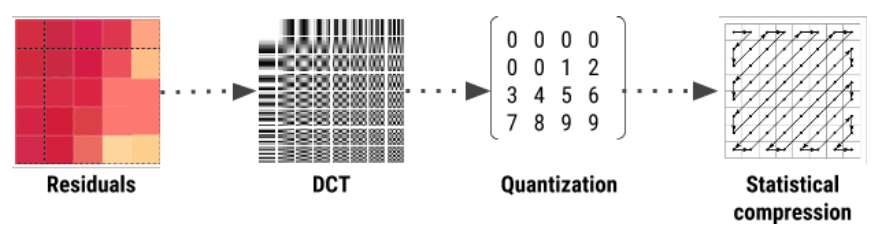
BPG
Similar to WebP, BPG is also derived from video coding technology (HEVC). The main features of BGP are as follows:
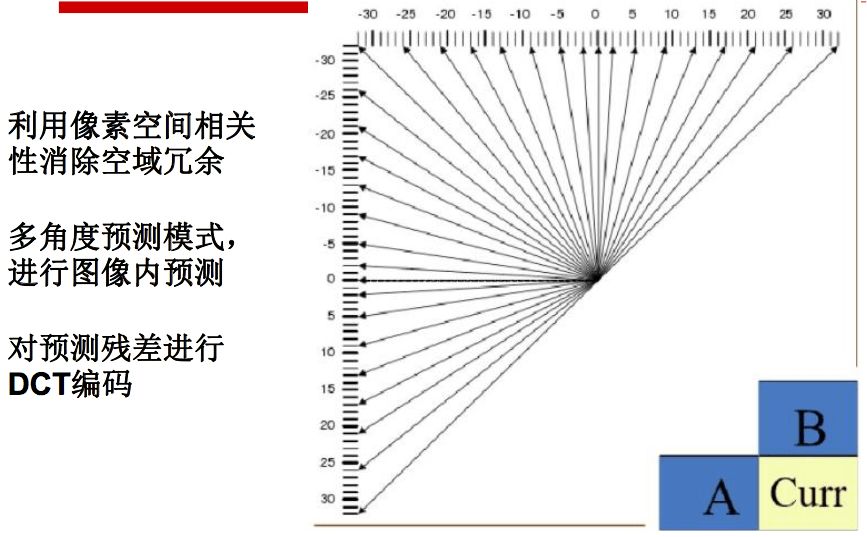
HEVC
The coding diagram of HEVC is as follows:
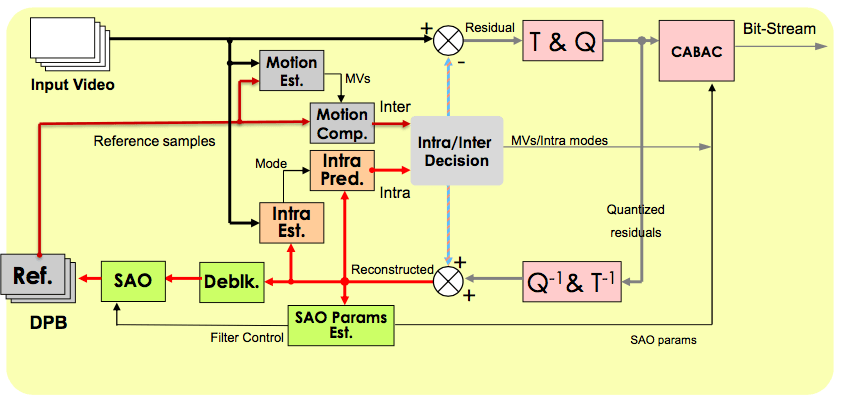
In the figure above, Ref. represents the reference sample. T & Q means conversion and quantification process, and Q-1 & T-1 are the reverse process. Deblk. is the abbreviation of Deblocking. HEVC divides the image into blocks and then encodes them. Therefore, discontinuities appear at the edges of blocks during reconstruction, which is called block effect. The deblocking process can reduce the block effect. SAO is the abbreviation of Sample Adaptive Offset. By analyzing the difference between the data after deblocking and the original data, it compensates for the loss caused by the quantization process and makes it as close to the original data as possible.
CABAC is adaptive binary arithmetic coding. Arithmetic coding uses the probability of symbol occurrence to encode a sequence of symbols into a number.
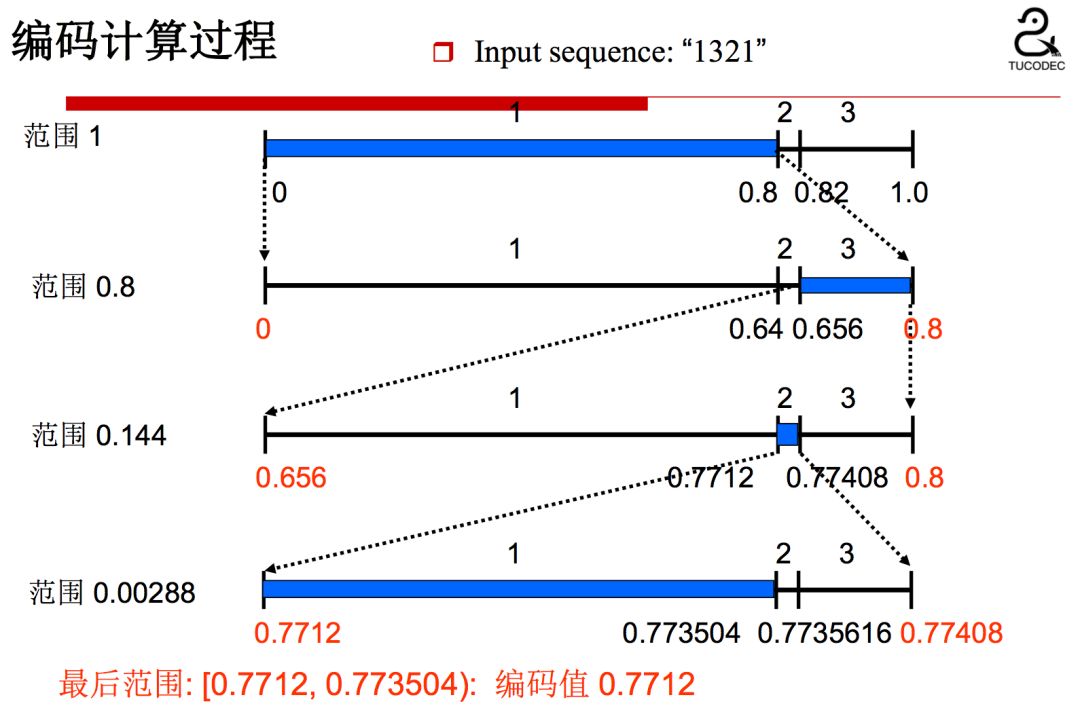
The corresponding decoding process:
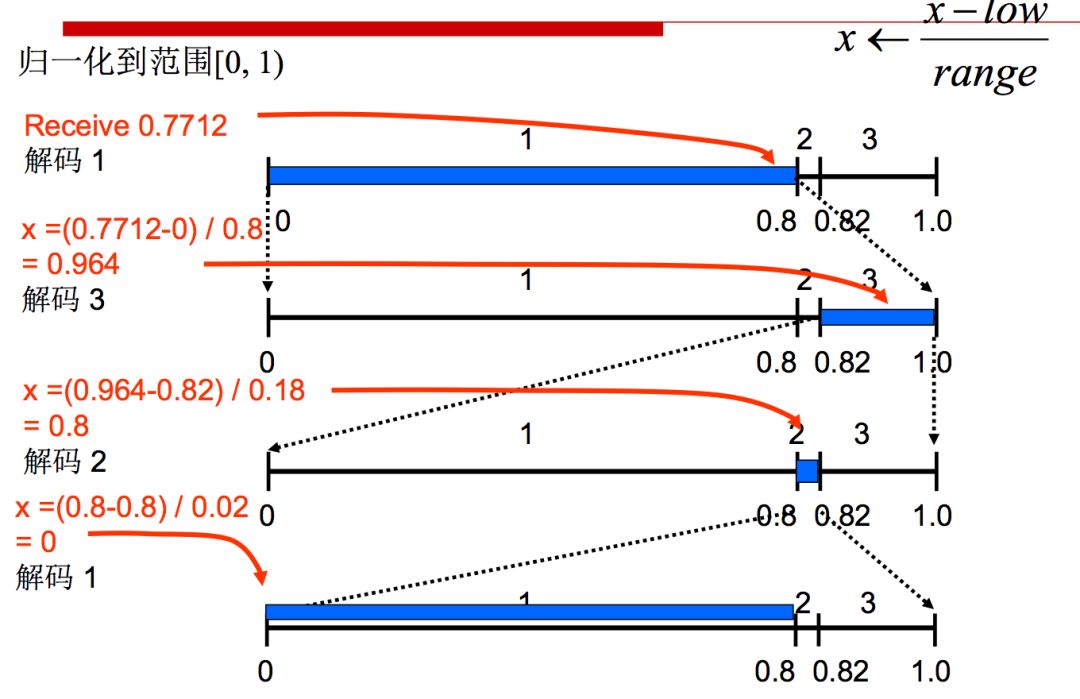
From the above coding and decoding process, we can see that the accuracy of the prior probability estimation has a great influence on the coding efficiency. HEVC uses a dynamically updated probability model to implement adaptive binary arithmetic coding.
In addition to intra-frame estimation and prediction (see the aforementioned BPG), HEVC video coding also needs to consider the relationship between frames such as motion estimation.
Deep learning image and video compression framework
Deep learning image compression framework
The following is a schematic diagram of a typical framework for deep learning image compression:
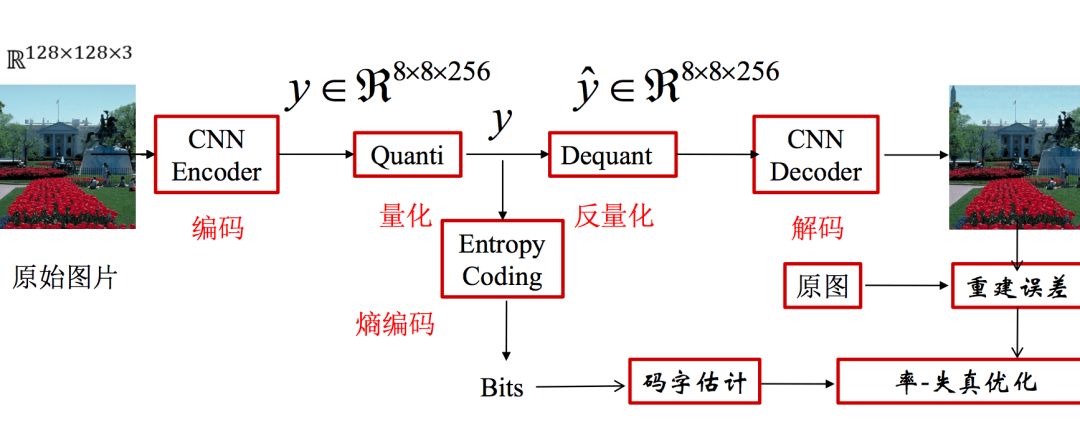
The specific role of each module in the above figure can refer to the explanation in How to Design an Image Compression Algorithm Based on Deep Learning.
Image compression data set
After designing the network model, you need to use images for training. Since image compression belongs to unsupervised learning and does not require manual annotation, the data set is relatively easy to collect. Whether it is crawling from the Internet or using a camera to shoot by yourself, it is not difficult to get a lot of high-definition pictures.
Commonly used test sets are:
Kodak PhotoCD data set, image resolution 768x512, about 400,000 pixels;
Tecnick data set, about 1.4 million pixels.
The CVPR 2818 CLIC data set has a wide range of image categories, resolutions ranging from 512 to 2048, and file sizes ranging from several hundred K to several M.
Deep learning video compression framework
The main difference between deep learning video compression and image compression is the addition of inter-frame prediction/difference.
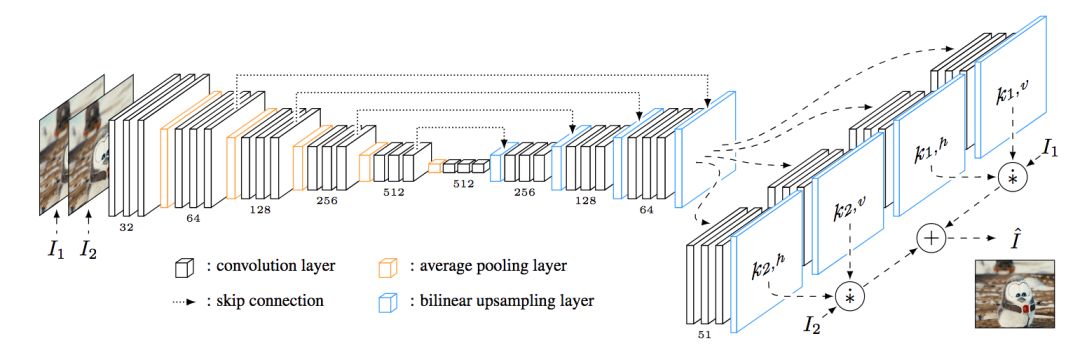
Inter prediction based on convolutional network
Inter-frame prediction can greatly reduce inter-frame redundancy. Taking 1 reference frame and predicting frame N-1 as an example, the constraint of inter-frame prediction is that the reference frame and the predicted codeword are much smaller than the codeword compressed separately for each frame:
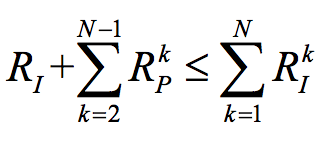
Introduction to the progress of deep learning image and video compression
The main development direction of deep learning image compression:
RNN
CNN
GAN
This part of the content can refer to the open class ppt and overview of the progress in the field of CVPR 2018 neural network image compression.
In terms of video compression, the research hotspot in recent years is to combine CNN with existing video encoders.
Coding unit selection
Liu Z, Yu X, Chen S, etc. published CNN oriented fast HEVC intra CU mode decision in 2016, using CNN to learn the classification of predictive coding unit modes (2N x 2N or N x N).
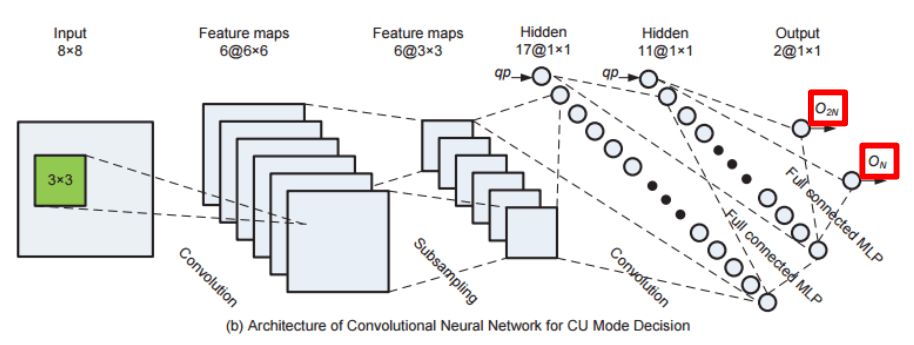
O2N, ON output is the price of rate distortion
Downsampling coding
The Fully Connected Network-Based Intra Prediction for Image Coding published by Jiahao Li et al. in 2018 performs block processing on video frames, performs downsampling on blocks that are suitable for downsampling, and does not perform downsampling on blocks that are not suitable for downsampling. Downsampling operation. After that, the down-sampled blocks are respectively up-sampled using CNN or DCTIF according to the situation to reconstruct the image. In order to achieve better results, the luminance channel and the chrominance channel use different network architectures.
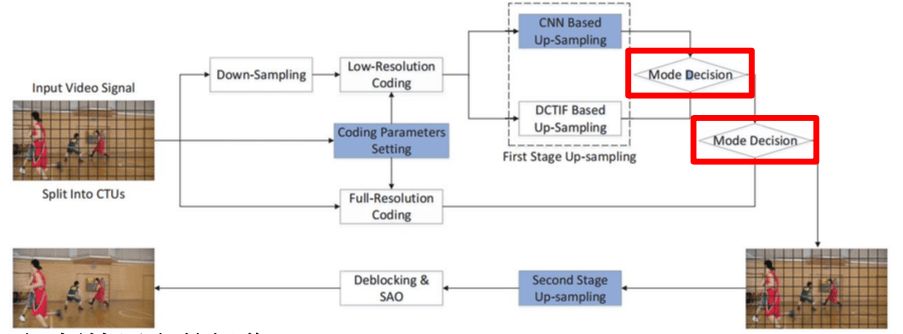
Video frame loop filtering and post-processing
In the CNN-based in-loop filtering for coding efficiency improvement published by Park WS and Kim M in 2016, the use of CNN has improved the effect of HEVC loop filtering (including deblocking filtering and SAO filtering).
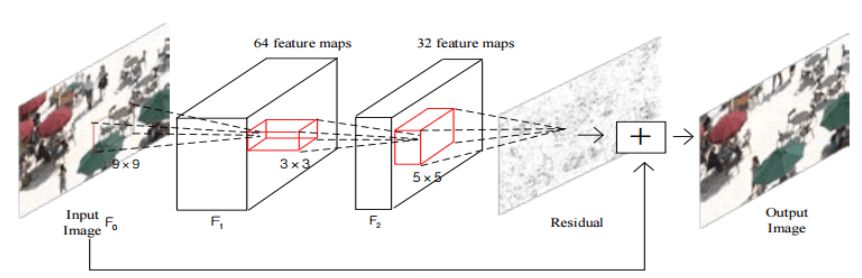
Similarly, Yuanying Dai et al. published A Convolutional Neural Network Approach for Post-Processing in HEVC Intra Coding in 2016, using the CNN network to improve the post-processing process of HEVC.
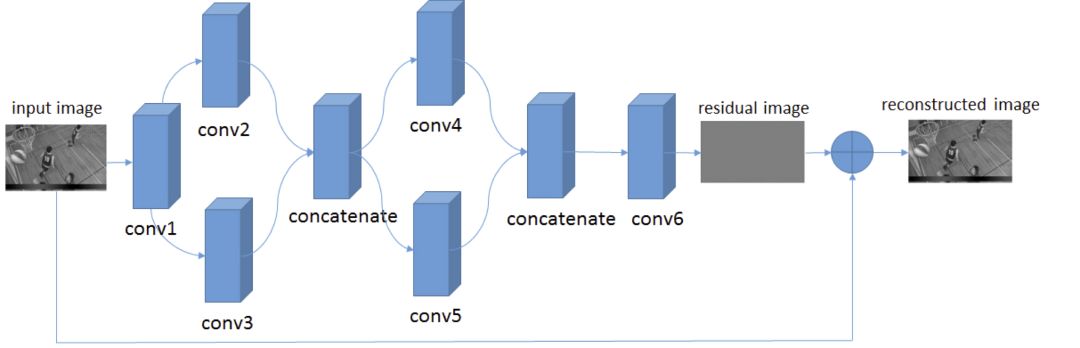
Advantages and disadvantages of deep learning video compression
Using deep learning for pure image compression has certain limitations in application scenarios. Deep learning has greater potential in the field of video compression. The main advantages of deep learning in the field of video compression are:
Able to achieve better transformation learning, so as to achieve better results.
The end-to-end deep learning model can learn by itself, while traditional video compression work requires a lot of manual design.
Traditional video compression methods usually use some heuristic methods for inter-frame prediction to reduce inter-frame redundancy. And deep learning can make predictions based on optical flow.
On the other hand, video compression based on deep learning will also encounter many challenges. For example, control the bits occupied by inter-frame prediction.
Tuya Technology Introduction
CVPR 2018 CLIC
In the CVPR 2018 learning image compression challenge, the Tuya team was one of the three winners, with MOS and MS-SSIM both ranking first.
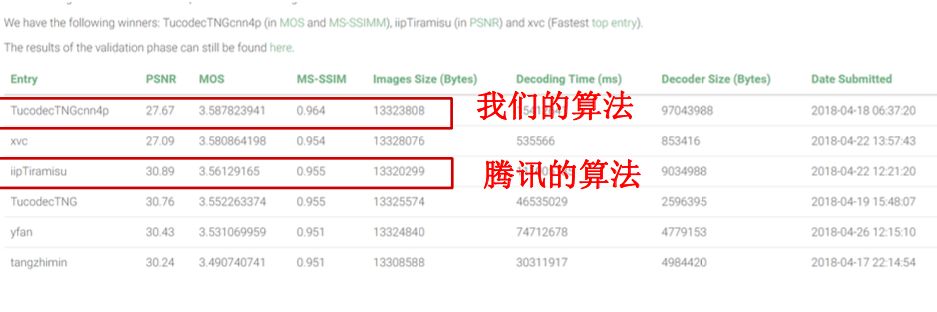
TucodecTNGcnn4p is based on an end-to-end deep learning algorithm, which uses a hierarchical feature fusion network structure, as well as new quantization methods and code word estimation techniques. The network uses a convolution module and a residual module, and the loss function is incorporated into MS-SSIM.
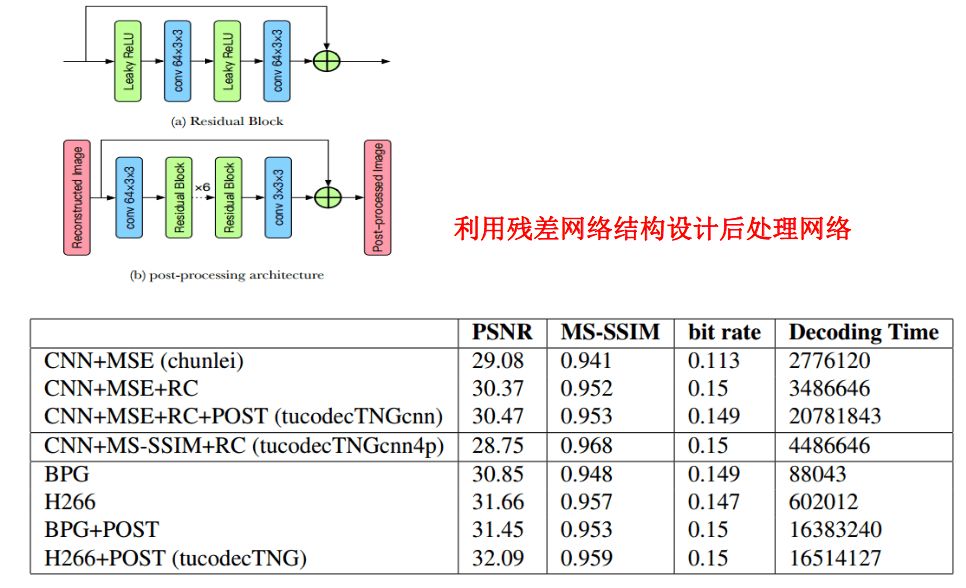
Image reconstruction based on deep learning super resolution
In this field, Tuya Technology focuses on super-resolution reconstruction at low bit rates. Because images inevitably have more distortion at low bit rates, the application of super-resolution reconstruction technology can alleviate the defects on these images and achieve better display results. The high bit rate image retains more details of the original image and is relatively not very suitable for applying super-resolution technology.
Video compression based on deep learning
As mentioned earlier, Tuya Technology believes that compared with image compression, deep learning has greater potential in the field of video compression. At present, Tuya Technology has been able to achieve results comparable to x265 in terms of video compression based on deep learning.
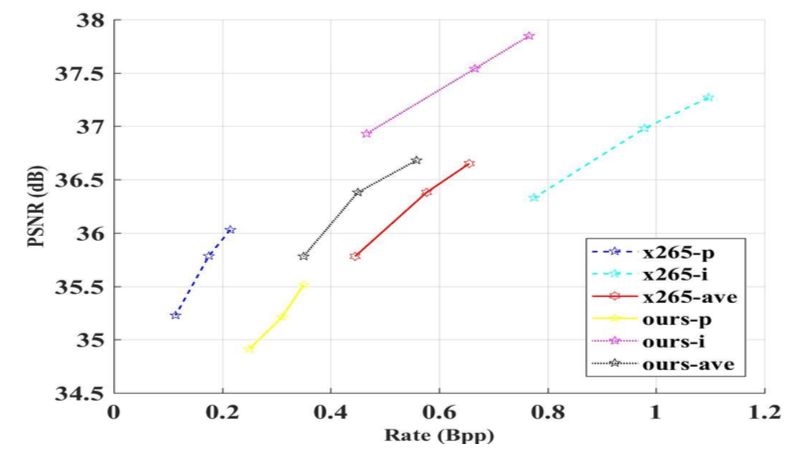
Structured storage based on deep learning
Compared with traditional methods, the computational burden of deep learning to encode images is heavier. However, on the other hand, image compression features can not only be used to reconstruct images, but also provide help for semantic segmentation and image classification.

question Time
Image compression based on GAN
GAN is mainly used in the field of image generation. But when performing image compression, GAN will encounter a problem, that is, it will change some details (generate some new details). Therefore, the choice of the technical direction of GAN often depends on project requirements. For example, for a human face image, if the region of interest is a human face, then very low bit rate compression can be used for the region outside the region of interest, and GAN is used to generate details when reconstructing the image.
Choice of quantification method
It is recommended that you refer to the relevant papers to choose by yourself. Because the choice of quantitative method is often related to other modules in the network. For example, if the activation output selected by the encoder part is binary (0, 1), then quantization is actually not that important.
Compression time
Generally speaking, compression algorithms based on deep learning have a disadvantage in terms of compression time on the CPU compared to traditional algorithms. But there are exceptions. For example, in the test of Tuya Technology, the CNN-based algorithm is actually faster than H266 on the CPU. Although H266 is a traditional algorithm, its complexity is actually very high.
In the future, with the increase in computing power of GPUs and dedicated deep learning chips, compression time will not become the biggest obstacle to the application of deep learning compression algorithms.
Computer Screen Protector,Screen Protector For Computer,Screen Protector,Best Computer Screen Protectors
Guangdong magic Electronic Limited , https://www.magicmax.cc