
Speech recognition modeling is an integral part of speech recognition because different modeling techniques usually mean different recognition performances, so this is the direction that each speech recognition team focuses on. It is precisely because of this that the models of speech recognition are also emerging. The language models include N-gram, RNNLM, and so on. In the acoustic model, it also covers HMM, DNN, RNN and other models...
In simple terms, the task of an acoustic model is to describe the physical changes in speech, while the language model expresses the linguistic knowledge contained in natural language. In this issue of the Hardin Open Course, Chen Wei, head of the speech technology department at Sogou Voice Interaction Center was invited to share the evolution of the speech recognition modeling technology along with the wave of artificial intelligence in the current round, hoping to help clarify the mainstream identification modeling context. Thinking behind.

Guest introduction: Chen Wei, expert researcher of Sogou’s desktop division, head of voice technology department of voice interaction center, responsible for research and development of sogou voice recognition, speech synthesis, music retrieval, voiceprint recognition, handwriting recognition, and other technologies. The research and development of voice technology of Sogou Confessions Engine is committed to improving the quality of voice interaction through the innovation of technology and products, and providing users with a superior voice experience.
Sogou's companion engine is an intelligent voice technology focused on natural interaction independently developed by Sogou. It was officially released on August 3, 2016. The technology integrates voice recognition, semantic understanding, voice interaction, and service provision. The function can not only listen to the audience, but also understand and think about it. This article will explain the use of speech recognition modeling technology in the companion engine.
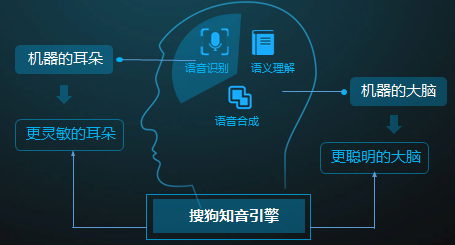
Figure 1 Sogou chat engine
Basic Concept Speech FrameTaking into account the short-term stationary characteristics of speech, the speech signal should be windowed and framed during front-end signal processing. The recognition features are extracted according to the frame. See Figure 2 for details. (Editor's Note: Frame-by-frame speech signals are extracted frame-by-frame for acoustic modeling. )
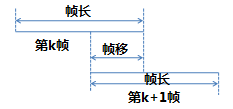
Figure 2 Speech frame division
Speech recognition systemAfter the speech signal is processed by front-end signal processing, endpoint detection, etc., speech features are extracted frame by frame. The traditional feature types include MFCC, PLP, FBANK, etc. The extracted features are sent to the decoder, in the acoustic model, language model, and pronunciation dictionary. Under the joint guidance, the most suitable word sequence is found as the recognition result output. See Figure 3 for the overall process. The formula for recognition is shown in Fig. 4. It can be seen that the acoustic model mainly describes the likelihood probability of the features under the pronunciation model; the language model mainly describes the connection probability between words; the pronunciation dictionary mainly completes the conversion between words and sounds, and the acoustic model is modeled therein. The unit generally selects a three-phone model and uses “Sogou voice as an exampleâ€.
Sil-s+ou1 s-ou1+g ou1-g+ou3 g-ou3+y ou3-y+u3 y-u3+y u3-y+in1 y-in1+sil
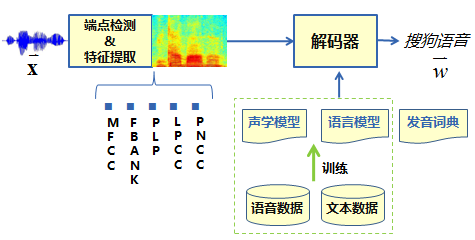
Figure 3 Voice Recognition System Process
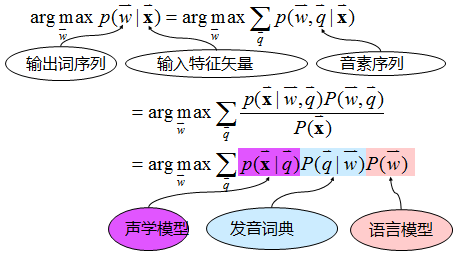
Figure 4 Principle of speech recognition
It should be noted that the input feature vector X represents the characteristics of the speech.
Mainstream acoustic modelingIn recent years, with the rise of deep learning, the acoustic model HMM (Hidden Markov Model), which has been used for nearly 30 years, has gradually been replaced by DNN (referring to deep neural network), and the accuracy of the model has also changed by leaps and bounds. From the three dimensions of the modeling unit, the model structure, and the modeling process, the acoustic modeling technology has shown obvious changes, as shown in Figure 5:
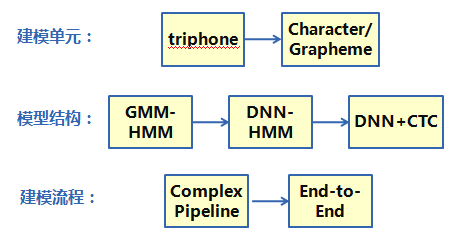
Figure 5 Acoustic modeling evolution summary
Among them, the superior feature learning ability of deep neural network greatly simplifies the process of feature extraction and reduces the dependence of modeling on expert experience. Therefore, the modeling process has gradually shifted from the complex multi-step process to simple end-to-end modeling. The impact of the process is that the modeling unit evolves gradually from state, triphone model to syllable, word, etc. The model structure changes from classical GMM-HMM to DNN+CTC (DNN refers to deep neural network). The intermediate state of evolution is the hybrid model structure of DNN-HMM.
HMMHMM was first established in the 1970s. The 80 's has been spread and developed and has become an important direction for signal processing. It has now been successfully used in speech recognition, behavior recognition, text recognition, and fault diagnosis.
In detail, the classic HMM modeling framework is as follows:
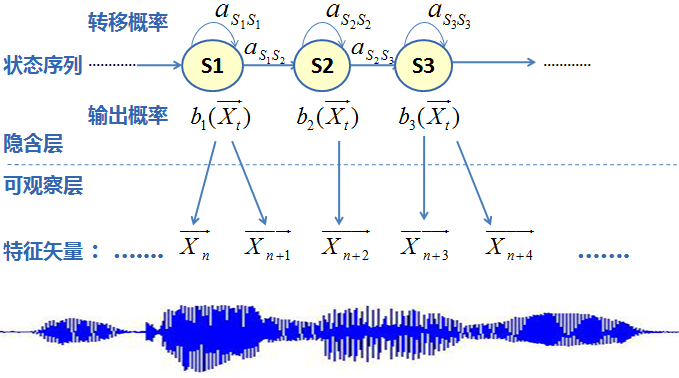
Figure 6 HMM modeling framework
Among them, the output probability is modeled using the Gaussian mixture model GMM, as shown in the following figure:

In 2012, Microsoft's Deng Li and Yu Dong introduced the Feed Forward Deep Neural Network (FFDNN) into the modeling of acoustic models. The output layer probability of FFDNN was used to replace the output calculated using GMM in GMM-HMM before. Probability leads the trend of DNN-HMM hybrid systems. Many researchers have used FDDNN, CNN, RNN, LSTM, and other network structures to model the output probability and achieved good results, as shown in Figure 7.
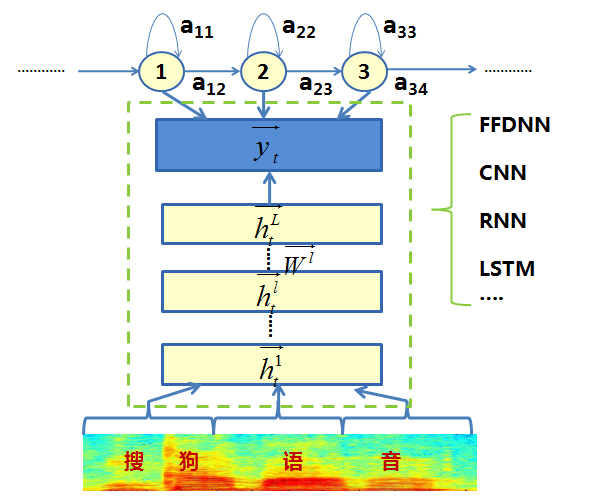
Figure 7 DNN-HMM Hybrid Modeling Framework
In the DNN-HMM modeling framework, the input features are used to model the long-term correlation of timing signals in the current frame to the left and right frames. The model output maintains the trihone sharing status (senone) often used by GMM-HMM. ) , the number of Chinese large vocabulary continuous speech recognition is generally set at about 10,000, as shown in Figure 8.

Figure 8 DNN-HMM modeling process
FFDNNThe model structure of FFDNN is as follows:
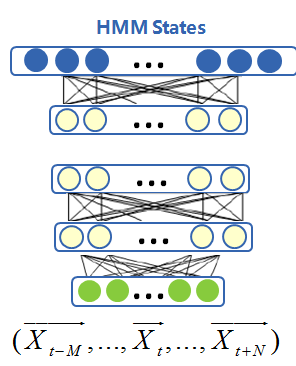
Figure 9 FFDNN modeling process
CNNEditor's note: In fact, the earliest CNN was applied only to image recognition and it was not until 2012 that it was used in speech recognition systems.

Figure 10 CNN modeling process
RNN and LSTMThe phenomenon of coordinated pronunciation of speech indicates that the acoustic model needs to take into account the long-term correlation between speech frames . Although the DNN-HMM above modeled the context information by means of a spelling frame, after all, the number of stitched frames is limited. The ability is not strong, so the introduction of RNN (recurrent neural network) enhances long-term modeling capabilities. In addition to receiving the output of the previous hidden layer, the RNN hidden layer also receives the hidden layer output of the previous moment as the current input. Through the loop feedback of the hidden layer of the RNN, long-term historical information is retained, and the memory ability of the model is greatly enhanced. The temporal characteristics of the speech are also well described by the RNN. However, the simple structure of RNN can easily cause problems such as gradient disappearance/explosion when BPTT (Backpropagation Through Time) is used in model training. Therefore, LSTM (Long and Short Memory Model) is introduced on the basis of RNN. LSTM is a special type of RNN. The long-term information was modeled by the special structure of Cell and three gated neurons, which solved the gradient problem of RNN. The practice also proved that the long-term modeling capability of LSTM is better than that of ordinary RNN.

Figure 11 RNN structure

Figure 12 RNN to LSTM
CTCThe above modeling techniques need to meet a condition when the model is trained. That is , each frame in the training data must be pre-determined corresponding label, ie, the serial number corresponding to the output state of the DNN, and the training feature sequence and the labeling feature sequence must be equal in length. In order to get the annotation, the existing model needs to be used to force alignment of the training data sequence and the annotation sequence, but the preparation of the annotation based on the big data training is time-consuming, and the accuracy of the alignment used model is often biased. The annotation used in the training will be There is an error. Therefore, the Connectionist Temporal Classification Criterion (CTC) was introduced to solve the problem of unequal lengths of labeling sequences and feature sequences. The forward-backward algorithm was used to automatically learn the model boundaries in speech features. This criterion was used in neural networks used for time series modeling. The combination of networks (such as LSTM) can be used directly for end-to-end model modeling, subverting the use of the HMM framework for speech recognition for nearly 30 years.
The CTC guideline introduces the blank category, which is used to absorb the ambiguity inside the pronunciation unit and highlight the difference between the model and other models. Therefore, the CTC has a very sharp peak effect. Figure 13 shows the content using the triphone-lstm-ctc model. The output probability distribution for the speech of "Sougou Speech" can be seen that most of the regions are absorbed by blank, and the identified triphone corresponds to a sharp spike.

Figure 13 CTC spike effect demonstration
It can be expected that the end-to-end identification technology based on CTC or CTC concepts (such as LFMMI) will gradually become the mainstream, and the HMM framework will gradually be replaced.
Other Modeling Techniques Language Modeling TechniquesAt present, the RNNLM technology has gradually been introduced into speech recognition. By modeling the longer history information, the RNNLM has better recognition performance than the traditional N-Gram technology, but considering the large vocabulary speech recognition Among them, if the complete replacement of N-Gram will bring about a large increase in the amount of computation and operation time, in the audio engine, RNNLM is used to reorder the N-Best candidate list output by N-Gram recognition.
Voice wake-up technologyThe current method for fixed wake-up words in the provoking engine is based on the DNN to perform end-to-end awakening word modeling, as follows:

Figure 14 End-to-end voice wakeup process
Although this method has achieved a very low false awakening rate, but the disadvantage is also obvious, the wake-up words can not be customized, so the sound engine, we use DNN extraction Bottleneck Feature for HMM-based wake-up model training, more traditional based on MFCC The method has also achieved good results.
About the future
Although the speech recognition modeling capability has been greatly improved, far-field, noise, accent, pronunciation habits (swallow) and other issues still exist, and it is very much in favor of Wu Enda's statement, from 95% accuracy to 99% despite There is only a gap of 4%, but it may change the way people interact, and it will achieve a transition that is rarely used and often used.
At present, the cost of acquiring voice original data is getting lower and lower. The industry is using tens of thousands of hours of annotated data to update models. In the future, 100,000 training data will become possible. How can we use data efficiently? The following are the main points: Considerations:
Data screening level: using unsupervised, weakly supervised, semi-supervised data for training, and more efficient selection of data for tagging, Confidence Engine has been using active learning methods for data screening ;
Operational level: Clusters based on heterogeneous computing efficiently perform model training on large data, and the upgrade of computing power has expanded from offline training to online testing .
Model level: The learning of large data requires a more capable model. The current composite structure based on multiple model structures (such as CNN-LSTM-DNN) has proved its feasibility, and the subsequent sequence-based learning framework based on Encoder-Attention-Decoder Combine with speech recognition .
At the same time, although speech recognition can now achieve high accuracy, the accuracy of the span from 95% to 99% or even 100% is a process of changing from quantitative to qualitative change, and it is also an important step in determining whether voice interaction can become a mainstream interactive method. However, some of the old problems in speech recognition still exist, and still cannot be fully solved technically. Therefore, product innovation outside the technology is also very important and can effectively compensate for the lack of accuracy.
Taking the Salon Engine as an example, it provides a voice correction solution to this problem. The errors that occur in the recognition can be corrected using natural speech. For example, if the user wants to say “my name is Chen Weiâ€, the recognition becomes “I Called Chen Wei, speaking through the voice, "Tong Dong-Chen Wei-Wei," will correct the recognition result. At present, with the iteration of many rounds of products, the voice modification already has an 80% success rate of modification, and it has already been applied to the Confidence Engine. In the voice interaction, voice modification capabilities are also integrated in the Sogou iOS input method.
Editor's Note: Summarizing the process of speech recognition system , summarizing the process of speech recognition system, acoustic modeling and language modeling is the most critical part, and current modeling techniques based on deep learning have taken model performance to a new stage. . However, as Chen Wei said, although the accuracy of speech recognition has reached a high level, there is still much room for improvement. What kind of model will appear in the future? Let us look forward to the emergence of new achievements in artificial intelligence, especially deep learning technologies.
This article is the original content of Lei Feng Network (search "Lei Feng Network" public number concern) , hereby declare

GF1 Diesel Generator Suppliers
Brief Induction
1) 3-24kw Series of ordinary diesel generating sets have been provided with high quality water-cooled diesel engine, those engine can work well in every kinds of conditions2) The structure of generating sets, the engine has been coupled with alternator through v-belt or coupled directly with alternator, both of them have been installed on the basis of anti-shock pad, The gen-sets have been fixed on the frame of shock pipes which has four wheels.
3) Other features It's easy to operate and maintain, control panel, capacitor type, voltage regulator, no-fuse circuit breaker, over-current protection, wheels type design, double-shaft balance design, electric starting.

GF1 Series Diesel Generator,GF1 Single Cylinder Diesel Generator,Single Cylinder Diesel Engine,Generator GF1 Series
FUZHOU LANDTOP CO., LTD , https://www.landtopco.com