
According to Zhang Feng, the author of this article, the article will decrypt in detail three issues that a chat robot needs to solve; 2) and the patterns that they use.
Introduction :
Chatbot is a word or an application that has been very hot in the recent period. Not only the major news media are cultivating the concept of bots, but also the giants have invested huge resources in research and development. It is even more common for arxiv to brush out bot-related papers. . The hype is speculation, PR is PR, and it has to be said that it is really difficult to find a really easy-to-use bot on the market. According to the areas involved, bots are divided into open-domain and task-oriented bots. The open domain has a lot to do, and it is more like a platform for what can be done. No matter what kind of needs you put forward, it can be solved. It means a bit of true AI, and task-oriented bots focus on doing a good job. Things to do, book flights, order meals, do passports, etc.
When it comes to open domain bots, the most popular ones are those bots that answer very ridiculously, such as the small yellow chickens that were active on major social networking sites many years ago. Nowadays there are a lot of active bots on the market. The bot companies that use deep learning to solve the bot technology are all solutions to this problem. They can't solve practical problems. They are able to chat with everyone, and many times the answer is that the head is not right and it is ridiculous.
Besides task-oriented bots, most of the customers on the market are customer service robots, banks, and e-commerce. They don't want to repeat the user's questions repeatedly. They respond with a customer service robot, and do not say how effective it is to develop a specific task. The bot needs a lot of work, and it needs a lot of maintenance later, because too much hand crafted features are used. The horizontal extension of the bot framework is relatively poor, and basically a set of scenes needs to be redeveloped. The cost of labor is too high.
The ideals of the bot are very full, and the scenes painted by the big companies are indeed beautiful, but the real bot has poured cold water. The higher the expectations, the greater the disappointment. If the media blindly touts the bot, it seems that the whole world will be a bot tomorrow. It will be of no benefit to the development of the bot. Holding and killing will only bring bubbles. After the rupture, everything will be as it was.
Powerful, open-domain bots are more difficult to implement in the short term, but if you reduce expectations, bots should not be a revolution in technology, and it should be done at the interactive level to be a rational attitude. One kind of entrance, maybe everybody no longer needs a carry-on terminal, only needs to find a identifiable, networked hardware, such as a mirror, you can perform many tasks, book tickets, buy things, and so on. At this time, bot played an entry point for the operation and a black box for executing various tasks behind it. We do not need to see the entire execution process, nor do we need to know what the principle is. We can accomplish some complexities through some simple language interactions. The task that the terminal needs to do is to feed back the results and receive input. The process of execution is in the cloud, and various bot clouds.
The key to this is to solve task-oriented bots and replace traditional manual features and templates with more data-driven solutions.
| Problem Description
The bot is a comprehensive issue that involves the following three main issues:
1, the response generation (selection)
The dialogue generation is the last step and is the output part. In summary, there are four solutions:
Solution 1 generates conversations directly based on the context. In this area, the most recent paper is very much. Especially after the seq2seq+attention framework has swept many tasks of the NLP, the benchmark generated by the dialogue is updated again and again by various models. The question generated by the dialogue is defined as a generative model based on a certain condition, typically predict words based on the context, and involves the problem of sentence generation. Evaluating a problem is a difficult problem.
Solution 2 Of course, some paper does not define dialogue generation as a language model problem, but rather a problem of next utterance selection, an alternative problem, given a context, given a utterance candidate list, and a choice from the list. As a response, of course, the difficulty of this type of problem will be much smaller, and evaluation is also very easy, but the data set to spend more effort to prepare it, and it is not good to be used in practical applications.
Solution 3 rule-based or template-based, the final form of the response is actually filled with a template, most of the things are given, only a few specific values ​​need to be filled. This type of solution is well suited for task-oriented bots, but excessive manual features and templates have made it difficult to port to other tasks.
Solution 4 query-based or example-based, response is from a database called the knowledge base, which contains a large number of rich example, according to the user's query, find the closest example, return the corresponding response as Output. This type of solution is very suitable for entertainment, funny bots, the core technology is to find more data to enrich the knowledge base to clean the knowledge base. After all, respnose is taken from someone else and may be funny, but most of them will not be right.
2, dialog state tracking (DST)
Some papers call DST belief trackers. This component is actually the core of the bot. Its role is to understand or capture the user intention or goal. Only when you really know what the user needs, can you make the correct action or response. For this section, there will be a Dialog State Tracking Challenge game. Generally speaking, a range of states will be given. Predicting which state the user belongs to through the context, what kind of demand, whether it is necessary to check the weather or to check the train ticket.
3, user modeling
Bots face specific businesses and they deal with real users. If they are simple FAQ bots, it may not be necessary to answer a few common questions. However, if it is other more complex and meticulous services, it needs to be given to users. Modeling, the same problem, bot to everyone's response must be different, this reason is very simple. User modeling needs more than simple user basic information and some explicit user feedback, but more importantly, the user's history conversations, these implicit feedback information. Just as it was before the recommendation system got fired up, everyone was selling things very well, but there were some smart people who started to analyze the user's behavior, not only those who liked it, but also those who were inadvertently left behind. Thus it is known what the user is potentially interested in, which is what the recommendation system is doing later. Modeling the user is to make a personalized bot. Each response generated has a distinctive feature of the user.
| Corpus
Large-scale corpora are used to train open-domain bot conversation generation models. Data sources are generally from social networking sites. For task-oriented bots, the customer's data is generally very small, which is one of the main reasons why it is difficult to directly apply the data-driven solution to the task-oriented bot.
[1] gives a survey of the bot training corpora. Interested students can read this survey.
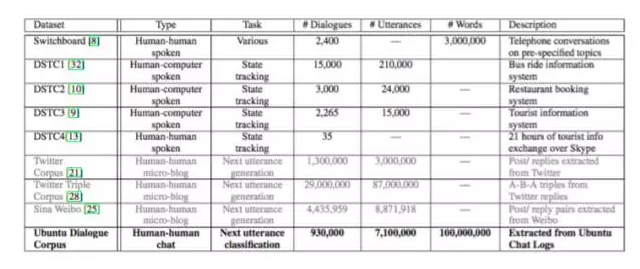
The figure comes from the article [13]. The English corpus is indeed more. Sina Weibo's corpus is released by Huawei's Ark Nork Laboratory [12]. If you generate bot data from Twitter or Weibo, the "conversational in nature" effect is not as good as the data generated from chat rooms like ubuntu chat logs, which is more suitable for training the response generation model because it is more natural and pollution-free. The article [5] also used a large Chinese language data, data from Baidu Post Bar.
| Model
There are too many papers to study bots. This is a very active field of research. The direction of subdivision is also very much. Next, introduce some models according to the research questions.
Seq2seq generation model
The most popular solution now is seq2seq+attention, where the encoder feeds in the user query feed, outputs a vector representation to represent the entire query, and then acts as a condition for the decoder, and the decoder is essentially a language model, generating the response step by step. ] Adopt this kind of scheme, google used a large number of parameters to train such a model, got a good bot.
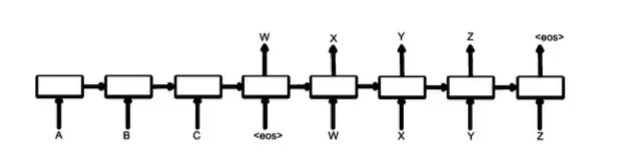
The typical seq2seq has a problem, that is easy to generate some "Ha ha" response, that is, some very safe, grammatical but no practical significance of the response, such as "I don't know!" and the like. The reason is that the traditional seq2seq uses the MLE (Maximum Likelihood Estimate) as the objective function in the decoding process, that is, if the most grammatical is generated, rather than the most useful, these safe sentences appear in the training corpus in large quantities. After the model is learned, Inevitably, such response is invariably generated, and the article [3] draws on some experience in speech recognition. In decoding, MMI (Maximum Mutual Information) is used as an objective function to improve the response of the response.
The article [4] thinks that the fundamental reason why a language model like RNNLM does not produce high quality speech is that it doesn't handle random features or noise hidden in utterance, thus generating next token (short term goal) and future. Tokens (long term goal) have a general effect.
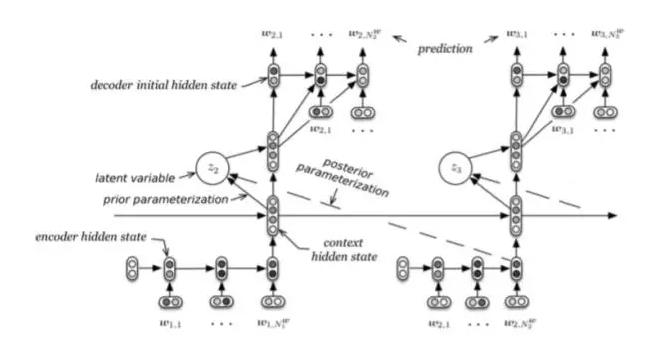
When generating each utterance, it is necessary to use four parts, encoder RNN, context RNN, latent variable, decoder RNN, and input and output in sequence. The latent variable here is similar to LSI in IR. Latent indicates that we can't tell exactly what they are, but it may represent a topic or sentiment, which is a representation of dimensionality reduction.
Article [5] proposed a method called content introducing to generate a short text response.
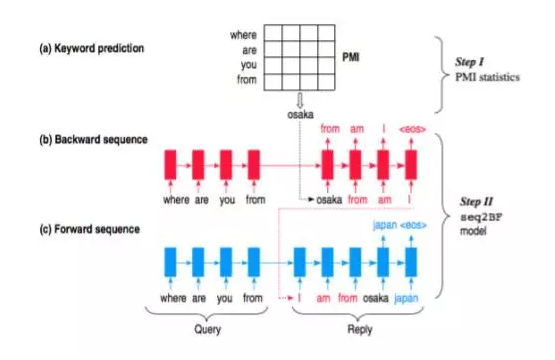
After step 1 is given a query, it predicts a keyword as the topic of the response. This topic is a noun. The keyword here does not capture complex semantics and grammar. Instead, it estimates a PMI based on each word of the query (Pointwise Mutual). Information) The highest noun as keyword.
The model of step 2 [5] is called Sequence To Backward and Forward Sequences. The first step is backward step. Given a query, it is represented by the encoder to get a context. The part of the decoder first gives the keyword as the first word, and then performs decoding. The generated part is equivalent to the part before the keyword word; the next step is forward step, which is also a typical seq2seq. The query is represented by the encoder as the context, and then the given backwards words and keywords are used as the first part of the decoder. Generate the second half. The entire process is simply described as follows:
Step 1 query + keyword => backward sequence
Step 2 query + keyword + backward sequence(reverse) => forward sequence
Step 3 response = backward (reverse) sequence + keyword + forward sequence
User modeling model
The problem [6] addresses the problem of inconsistent responses in multiple rounds of conversations. Considering user identity (such as background information, user portrait, age, etc.) into the model, a personalized seq2seq model is constructed for different users. , and the same user for different please generate a different style of response.
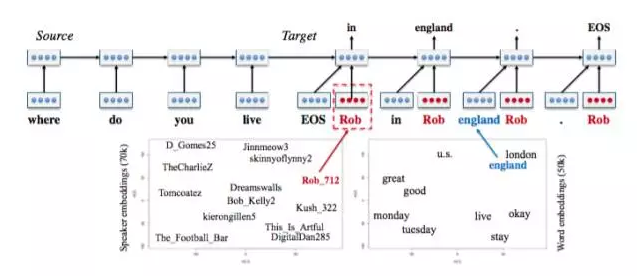
The model of [6] is called Speaker Model, which is a typical seq2seq model. The difference lies in adding a speaker embedding in the decoding part, similar to the word embedding, just to say that the user is modeled here. Because the user's information cannot be explicitly modeled, an embedding method is used to obtain the speaker vector through training. The left diagram below is the representation of the speaker vector on the two-dimensional plane, and the user with similar background information is used. It will be very close, with the word vector a truth.
Reinforcement learning model
The use of reinforcement learning to solve the problem of man-machine dialogue has a long history, but with AlphaGo's hype, deepmind has brought reinforcement learning back to the stage and combined with deep learning to solve some of the more difficult problems.
Enhancing learning using long term reward as an objective function will enable the model to predict a higher-quality response after training. The article [7] proposes a model framework with the following capabilities:
1. Integrate the developer's custom reward function to achieve the goal.
2. After generating a response, you can quantitatively describe the impact of this response on subsequent phases.

The two bots in the dialogue, given an initial input message, and then bot1 generates 5 candidate responses based on the input, in turn, because each input will generate 5 response, as the increase of the turn, the response will exponentially increase Here, in each round of conversation, select 5 out of the response for the current round with sample.
Train a good seq2seq as an initial value on a large data set. Use enhanced learning to enhance the model's ability to implement custom reward functions to achieve the desired effect.
The model in [7] can generate more rounds of conversations without prematurely falling into an infinite loop, and the resulting dialog diversity is very good.
Task-oriented seq2seq model
Existing task-oriented bots are mostly rule-based, template-based, or example-based, or use data-driven solutions that are very rare. Articles [8] and [9] are attempts to use deep learning techniques on individual parts of the bot, and give practical solutions.
The article [8] starts with a well-known scenario. How an experienced customer service brings a new customer service is divided into four phases:
1. Tell the new customer service which "controls" are available, such as how to find customer information, how to determine customer identity, and so on.
2. The new customer service imitates learning from the good examples made by the old customer service.
3. The new customer service began to try to serve customers, and the old customer service promptly corrected his mistakes.
4. No matter if the old customer service is letting go, the new customer service will serve the customer alone, keep learning, and accumulate experience.
The model framework of [8] is designed according to the above process:
The developer provides a series of alternative actions, including a response template and some API functions that are used by the bot.
A series of example dialogues are provided by the experts and they are learned using RNN.
Randomly generates a query with a simulated user, and the bot performs the response, which is corrected by the expert.
The bot is on-line service, dialogues with real customers, and improves bot service quality through feedback.

A complete workflow is described by the figure above. The specific steps are shown in the figure below:

During training, SL is supervised with some high-quality data, and RL is used to optimize the model to obtain higher-quality results.
The article [9] balances the advantages and disadvantages of the two popular schemes, and proposes a set of valuable and practical seq2seq solutions.
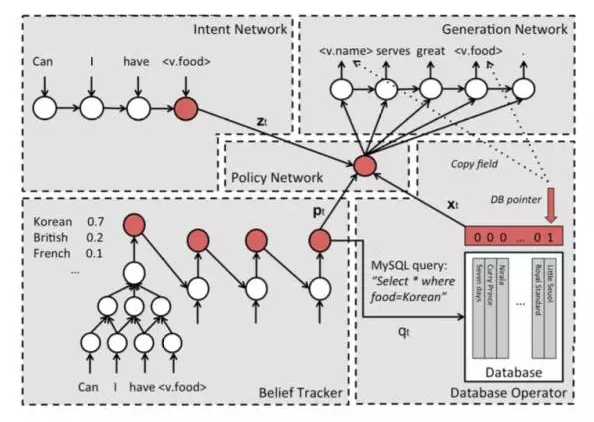
A total of five components:
1, Intent Network
This part can be understood as the encoder part of seq2seq, which encodes the user's input into a vector.
2. Belief Trackers
Also known as Dialogue State Tracking (DST), is the core component of the task-oriented bot. The Belief Trackers in this article have the following effects:
Support for various forms of natural language is mapped to elements in a limited set of slot-value pairs for querying in the database.
Track the bot's state to avoid learning data that has no information.
Using a weight tying strategy, the need for training data can be greatly reduced.
Easily expand new components.
3, Database Operator
The input of the database query comes from the output of Belief Trackers, that is, the probability distribution of various slots. Take the largest one as the input of the DB, perform the query, and obtain the corresponding value.
4, Policy Network
This component is like a glue and serves to bond the other three components above. The input is the output of the above three components and the output is a vector.
5, Generation Network
The last component is the generative model, which is essentially a language model. The input is the output of the Policy Network. The output is the generated response. After some processing, it can be returned to the user. The processing here is mainly to restore the slot in the response, such as s.food, to a real value. This step, like step 10 of article [8], restores specific values ​​to the entity.
It is impossible to completely solve task-oriented with end-to-end. It must be done in a framework or system with this seq2seq solution. Articles [8] and [9] give Great inspiration.
Knowledge Sources based model
A pure seq2seq can solve many problems, but if you add a related knowledge source to seq2seq for a specific task, it will make the effect much better. The knowledge here can be an unstructured text source, such as ubuntu manpages in article [10]. It can also be structured business data, such as the database in article [9], or it can be a source data and business data. Extracted knowledge graph.
The article [10] author defines the bot task as next utterance classification, a bit like the question answering task, given a context and a response candidate list as alternative answers, through the context to select the correct response from the candidate list. The contribution of this paper is to introduce task-related external professional knowledge base on the basis of context, and this knowledge base is unstructured.
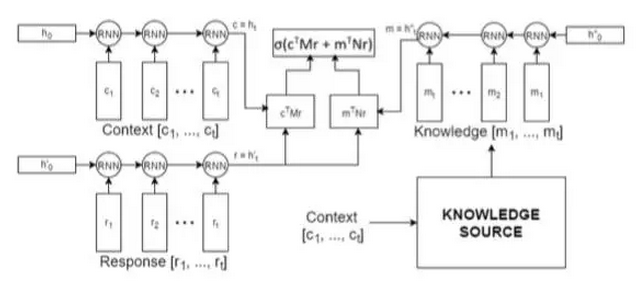
The model is composed of three rnn encoders, one rnn to encode context, one rnn to encode response, and one rnn to encode knowledge, and then combine the predictions and select the most suitable response. The model is called a knowledge encoder. Because the data set uses datasets related to ubuntu technical support, external resources use ubuntu manpages.
Context sensitive model
The model of [11] is relatively simple, but the problems considered are of great significance. The modeling of history information is very helpful for bots in solving practical engineering applications, and also directly determines whether your bot can work. The author describes the history context as a bag model rather than the rnn we often use, and then passes the context and user query through a simple FNN to get an output.
| Evaluation
Bot response evaluation is difficult, although it can be used to refer to the automatic evaluation method of machine translation BLEU, but the effect will not be too good. Almost every paper will spend money to hire artificial evaluations, design a set of evaluation mechanisms to score points, and artificial evaluation is more convincing. This is especially true for practical engineering applications. Users say that it is really good. Instead of simply holding your own, biased metrics, compare yourself to several methods or other company bots to illustrate yourself.
| Thinking
After reading some papers and communicating with the engineers who were working on the bot application, there is a bit of thinking and it is summarized as follows:
1. Do you want to do bot? A popular saying is that there are no good bots on the market. To solve the bot problem requires many technologies to advance at the same time. It may take a very long time. It is simply absurd to use this thing to do business. My personal opinion is that solving the bot of a specific task, combining current advanced technology, and doing some framework tools is not so far away. Although it is not easy, it is very meaningful and solves the bot problem in the vertical domain. It is possible to solve the open domain bot problem. It is also because it is not easy to raise the threshold. Only real opportunities will emerge. Some very technical companies will be born.
2, open domain or task-oriented? If it is me, I will choose the latter because the former is only a dream, an unattainable dream, and requires more breakthroughs on the technical level. Task-oriented is more specific, more practical, and provides solutions for specific businesses. Many companies have already done it. Although a universal or scalable solution has not yet emerged, it must be a trend and a new one. A generation of companies that do bot's opportunities.
3. Why is the task-oriented bot difficult and where does the direction come from? End-to-end is an idealized model. Using the deep learning model to “capture†some features from a large amount of training data, “fitting†some functions, although it can get very good results, and it is indeed very convenient to use. , but you can't get enough data in a specific task. After the data is small, pure end-to-end becomes very tasteless. However, in real situations, many companies have certain data and bot requirements. Therefore, the mature solution is to design some features, templates, and rules for your specific business. When the customer's business changes, it needs to Continuously maintaining the existing bot system is time-consuming and laborious. Real scenes often involve a lot of structured business data. It is impossible to generate responses based on context directly and violently. Both articles [8][9] give very enlightening solutions. The application of end-to-end to the local rather than the overall, coupled with Information Extraction and Knowledge Graph technologies, to achieve a highly available framework, this should be the direction of the development of task-oriented bot.
4. What factors should be related to the generation of the response? The quality of the response quality needs to be linked to the following features: (1) user query, user's question, what the user is asking in this round of dialogue, and accurate understanding of the user's intentions. This is crucial. (2) user modeling, modeling the user, including the user's basic information, and more importantly, the history of the user history conversation logs, this work is difficult, but at the same time also very horizontal, is also a technology company to prove their own technology A way to go. The mining of logs is very common nowadays, and it is not necessarily done well by everyone. The logs here are not general set and structured indicators, but unstructured text logs. It is more difficult to excavate. Another point, also seen in paper, user emotion, sentiment analysis is more research in the nlp task, the user's emotions are directly related to the success or failure of sales, if the technology is sufficient cattle, the factors can be considered enough, for the user The analysis is clear enough. It's not a good idea to hung history students in the model, because history is constantly increasing, which causes the model to have problems in capturing information. A better approach might be to build a user profile or something, and precipitate history as a vector. A representation, or a knowledge graph, represents a user. With this ability of the bot, it is a politely personalized bot. (3) Knowledge, external knowledge source, when it comes to a specific business, business data is also a kind of knowledge. How to model knowledge into a model can be more professional and accurate when generating a dialogue. It is also a very important issue. The bot is a comprehensive problem, not only the difficulty of the system framework, but also difficult to model.
5. I have always felt that being a person and watching a problem cannot be extreme. The world is not black and white, but it is a continuous value between the two. It's impossible to say either make an open-domain giant bot, or a bot that doesn't have any specific features. You can't just see that the existing bot is immature, and the bot in the fantasy is out of reach and it's black. In this area, it is also ridiculed that people can actually get investment. The quarrels are meaningless. What really makes sense is to dig deep into this field, find pain points and difficulties, break them one by one, and continue to push forward the development of this field, instead of being as boring as some people watching lively streets! Before the breakthrough in many fields, it seems that we can't see the light. But after a few years, many problems that were difficult to solve at the time were not all a piece of the Red Sea. Making a general-purpose bot may be a difficult task for a long time, but there is still hope for a highly available and scalable bot solution that does not require excessive self-confidence and does not need to be self-conceited. It is.
Lei Feng Network (Search "Lei Feng Network" public concern) Note: This article is reproduced by ResysChina authorized, please contact the original author if you need to reprint.
270W Solar Panel,270 Watt Solar Panel,275W Solar Panel,280W Polysilicon Solar Panel
Zhejiang G&P New Energy Technology Co.,Ltd , https://www.solarpanelgp.com